High Level Synthesis for Deep Learning
Artificial Intelligence defeating the best human player was perhaps one of biggest breakthroughs of this decade. Recent years have witnessed great achivements in the field of AI, with machine learning based systems delivering performance comparable to or even better than humans. So the question arises, what is this new AI algorithm ? Interestingly, AI and machine learning is not new. The core concepts behind the success of these algorithms have been there for decades. But the lack of labelled datasets and computing systems, prohibited large scale implementation and execution of these. Recent success of these algorithms can be attributed to availability of huge open source labeled datasets and the relentless research in the fields of deep learning and computing systems.

As engineers, we are always concerned with the computation requirements for any program. It turns out that, to classify a 220x220 image, AlexNet (a decent sized neural network) does ~22 G-Ops! So, the current generation of general purpose hardwares can never meet the performance requirements for these algorithms. This has kindled an interest in the research community to look for architectures best suited for deep learning accelerators. In this post, we will go through the findings from one of my projects in which we looked into high level synthesis tools for fast architectural design space exploration.
A closer look at Deep learning
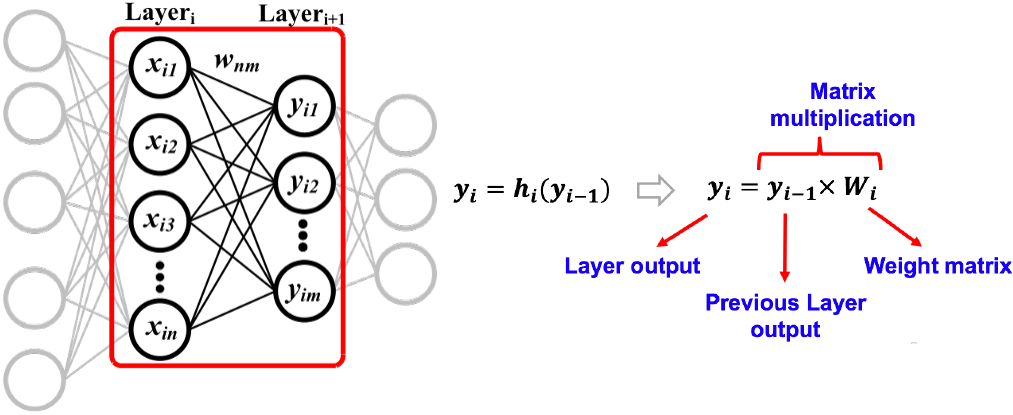
Deep learning depends on deep layered structures, with each layer feeding data to subsequent layers. The figure above illustrates a very simple fully connected feed forward network. Its fully connected because each node (neuron) in any layer is connected to every node in the next layer. Its feed forward because the data movement is always in one direction (input – output) and there is no feed-back path. Each layer in the neural network is essentially doing a matrix–matrix multiplication on the input data. So a accelerator of deep networks should be very efficient at matrix multiplications. However, this is not a very simple task. Major complications that make the life of a hardware engineer difficult are:
- As the model sizes grows (~100s of MBs), onchip storage of the parameters and intermediate results is not possible. So they are stored on external memories (DDR). So fetching the data is now associated with huge latency. Memory bandwidth bottleneck caps the maximum performance you can achieve.
- Due to the humongous amount of computations involed, the hardware should have huge parallelization capabilities. Due to dependencies between layers, there is an upper limit to which we can parallely execute the program.
- Another thing to keep in mind is that as fetching data is associated with huge latency numbers, the accelerator should be designed so as to maximize data reuse.
HLS: High Level Synthesis
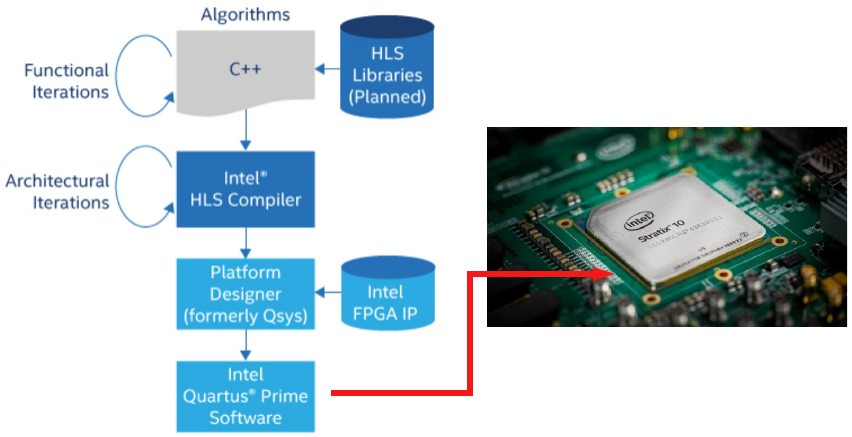
Using Verilog / VHDL to write codes for hardware design gives the designer the ultimate flexibility and often results in very high performance. However, the developement time when using verilog/VHDL is high. Because of this, during architectural exploration phase when the design space is searched over, using verilog / VHDL is not always the best option. In contrast, the HLS compilers provided by Altera and Xilinx take in untimed C++ as input and spit out production-quality register transfer level (RTL) code that is optimized for their FPGAs. Also the verification time is orders of maginitude faster than RTL because of the increased abstraction level for FPGA hardware design.
In this post, we will discuss HLS compilation tools from ALtera. The tools can be downloaded from Altera’s Website. You will also need to download the Board Support Package (BSP) from your FPGA board vendor’s site. In my case it was Terasic DE5-Net with Altera Stratix V FPGA. Once you have installed the OpenCL SDK from altera and the BSP from the board vendor, try running aocl diagnose acl0 to make sure that your setup is working properly. In case it fails, I recommend contacting the vendor’s support team immediately. In my case, they fixed driver version related issues in a few days while I wasted 15 days looking for solutions on internet.
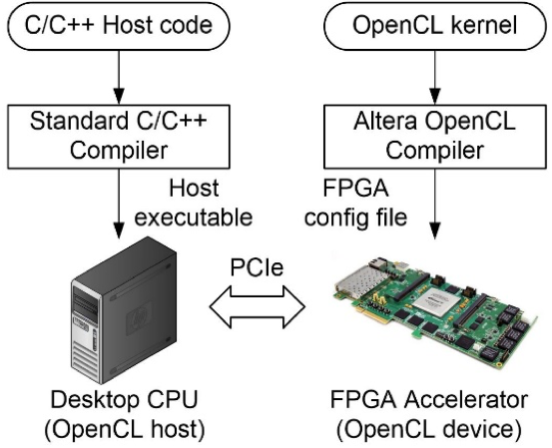
The framework consists of two parts:
- The Host: Host is any CPU with PCIe interface. On some boards (CycloneV), the ARM cores on SoC can also act as host. The host code is in C++ and can use all the C++ libraries. Components of the algorithm demanding high computations can be off-loaded to a FPGA device for accleration.
- The Device: The FPGA device is connected to the host using the PCIe interface. Hardware kernels are written using OpenCL constructs and compiled to RTL using HLS tools. All the perifhery and glue logic like DMA, Memory Controller, Handshaking signal etc. are taken care of by HLS tools, so we only need to concentrate on the core logic.
HLS Deep dive: Matrix multiplication
We will take an look at optimization knobs provided by HLS using an toy example of matrix multiplication. It is one of the examples from Altera and should be included in the BSP from vendor. It consists of two main files:
- main.cpp – The host program file
- matrix_mult.cl – OpenCL kernel file
OpenCL kernel
